Self-Healing DevOps Part III: Automated Blue-Green Deployment Remediation
Categories
Infrastructure & Operations
You’ve seen in our previous two blogs how xMatters and Dynatrace join forces to use self-healing DevOps to repair process crashes and prevent full disk errors. Now, in the final blog of our series, we’ll dig into how to automate remediation across blue-green deployments.
Balancing innovation & risk
According to Dynatrace’s 2018 Global CIO Report, 73% of CIOs say the need for speed in digital innovation is putting customer experience at risk. The same report noted the organizations polled pushed three releases an hour.
To meet the high volume of new releases while accounting for regular risks like performance degradation and process crashes, many DevOps teams use blue-green deployments as part of their continuous deployment practices.
To quote DevOps thought leader Martin Fowler, “The blue-green deployment approach… [ensures] you have two production environments, as identical as possible. At any time one of them, let’s say blue for the example, is live. As you prepare a new release of your software you do your final stage of testing in the green environment. Once the software is working in the green environment, you switch the router so that all incoming requests go to the green environment – the blue one is now idle.”
So how do you automate remediation across two production environments to ensure you take automated, preventative actions?
Scenario #3 | Autoremediation for Blue-Green Deployments
Dynatrace and xMatters remove the stress from blue-green deployments.
Step 1 | Application Performance Monitoring
In an era of increasingly complex environments, Dynatrace monitors across your entire application infrastructure to keep proverbial eyes on everything at once. With Dynatrace in place, resources quickly and easily see when the new release pushed to the blue environment is having a detrimental effect on the performance of interrelated microservices across this environment, slowing applications to a near-grinding halt. Dynatrace surfaces this issue, including pertinent data about the buggy release itself as well as critical information on how it’s impacting other services – and where they live.
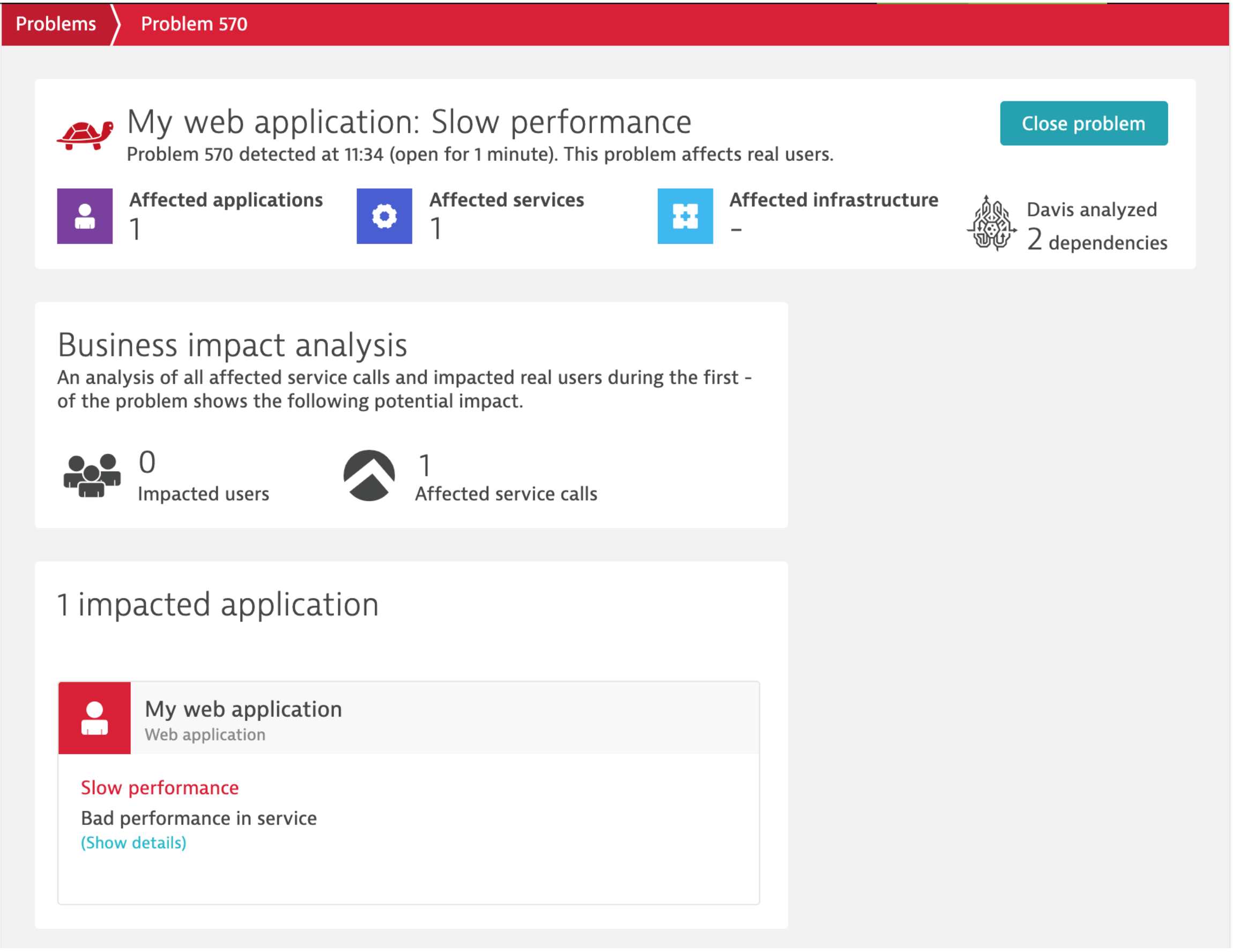
Dynatrace detects the affected application and services and their Davis AI-engine surfaces dependencies.
Step 2 | Control Plane
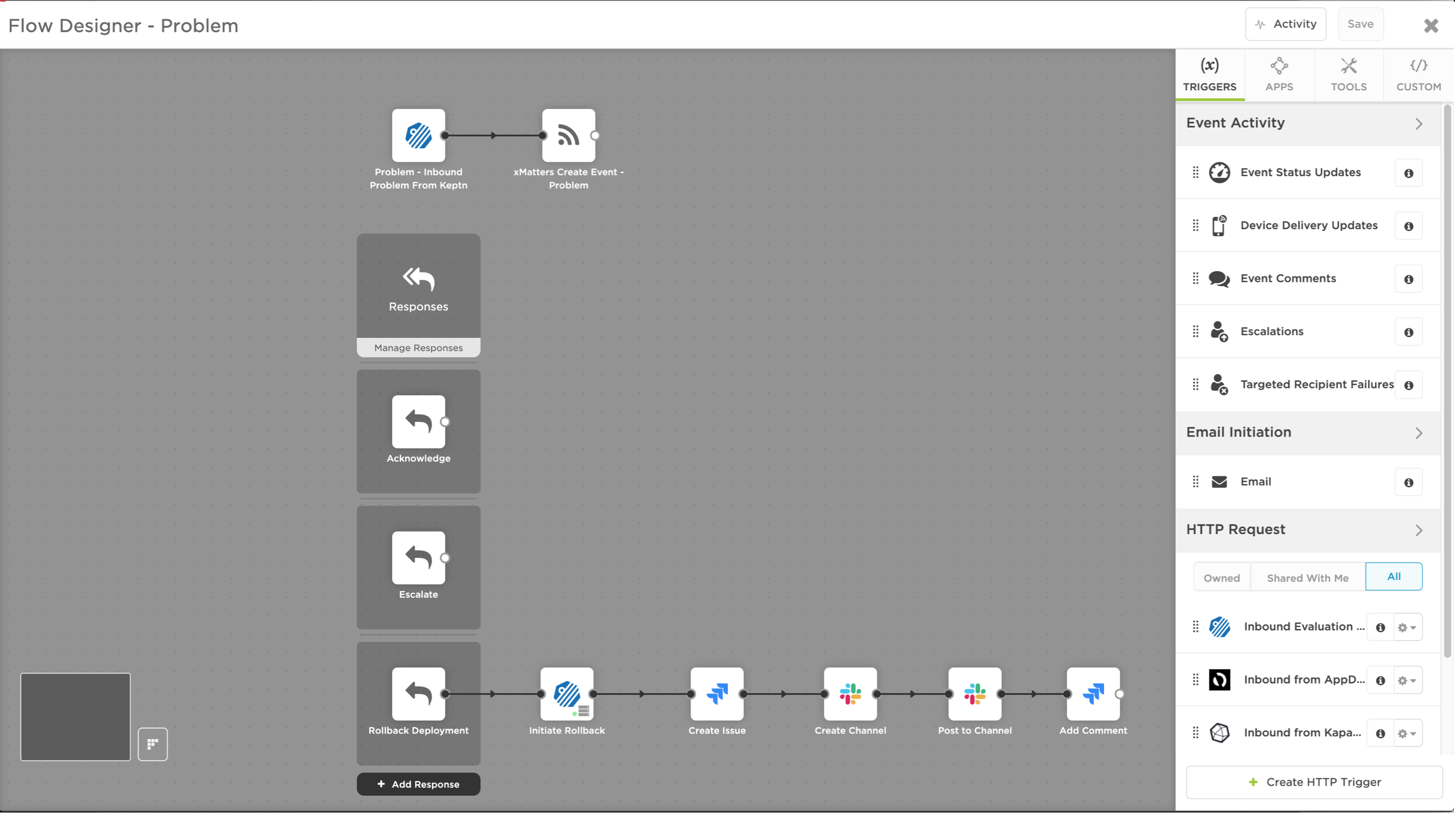
The code that was shipped may have passed pre-deployment rounds of testing, but it’s now impacting other services running. The team must take Immediate action to revert to the previous version in the parallel, green environment with Dynatrace’s keptn. In the words of Andreas Grabner of Dynatrace, this new product “…not only orchestrates Continuous Deployment, but it also orchestrates Continuous or Automated Operation.” So, as Dynatrace surfaces the incident, keptn simultaneously captures the issue data and triggers an xMatters workflow. This allows the developer on-call to take swift action and fix the problem.
Step 3 | Incident Response
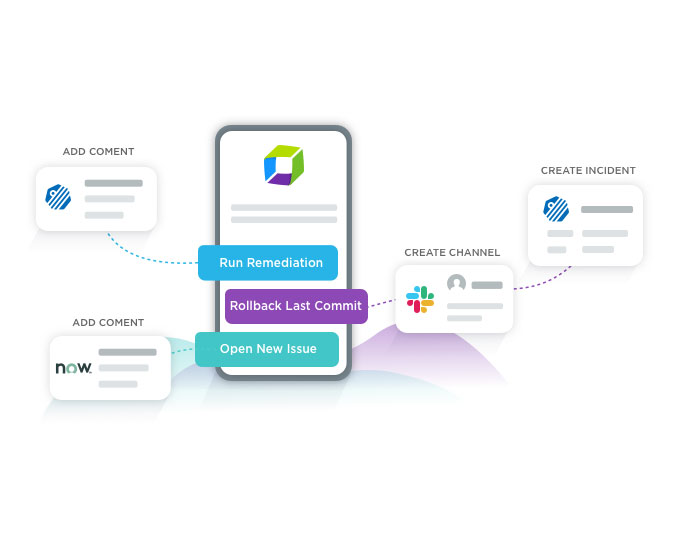
Triggered by keptn, xMatters references the developer on-call schedule and, in moments, alerts the proper resource. The notification automatically includes the full context of the issue even on a mobile device, including errors caused, impacted systems, and level of severity. Now the resource can quickly investigate the situation and determine the best response action. With the push of a button, the resource launches a remediation workflow across the prescriptive DevOps toolchain to automate rollback to the green environment through keptn. The same workflow also embeds critical information into the proper channels like Slack, Jira Service Desk, and Dynatrace.

Keptn triggers the xMatters alert with contextual incident information.
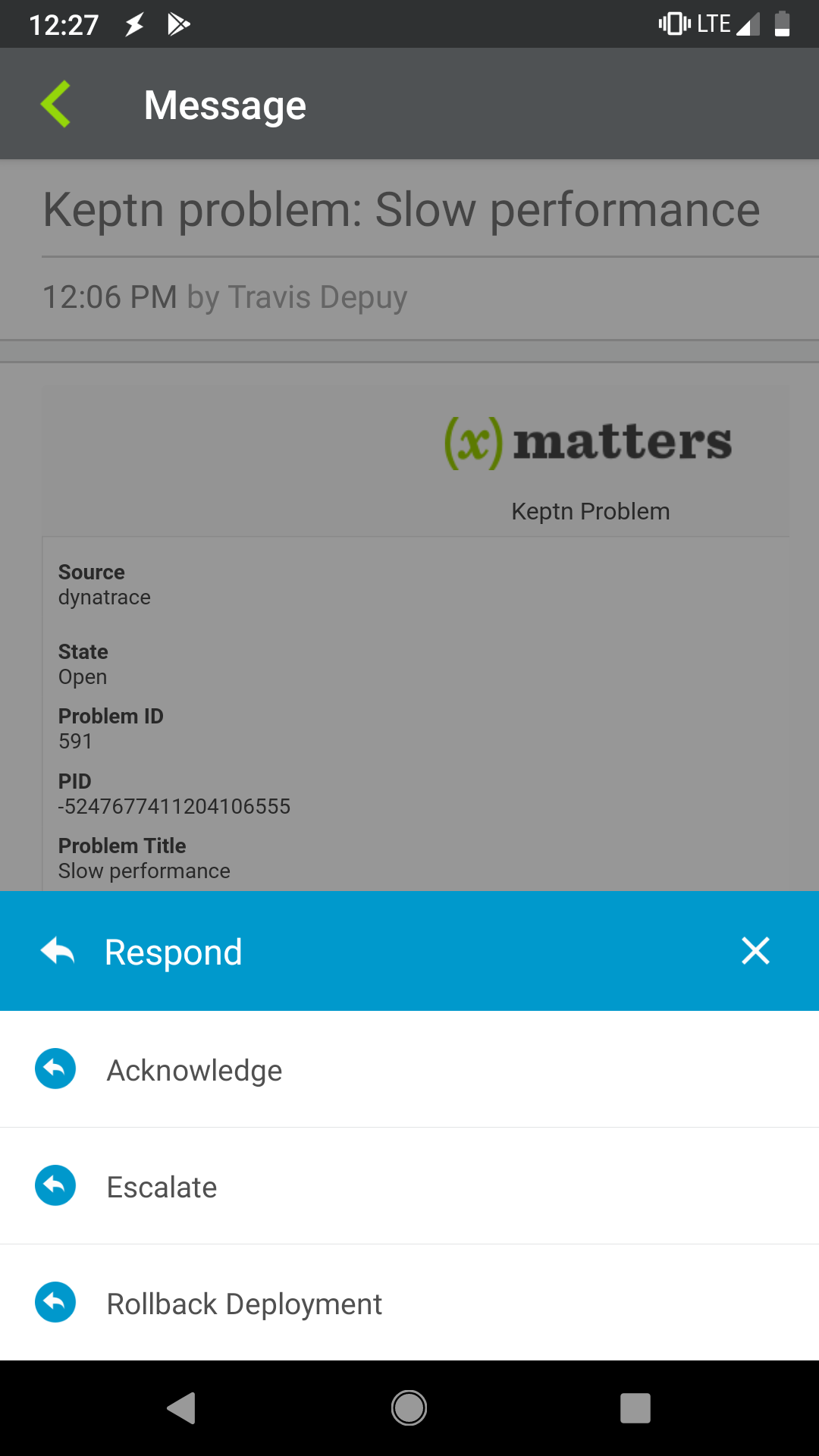
xMatters provides on-call resources actionable responses to launch the proper response in the click of a button.
Step 4 | Service Desk
Fully automated and without any manual intervention, xMatters creates a ticket in the service desk (or multiple service desks, if your organization uses more than one), embedding incident information into the ticket and automatically updating the status and comments therein so it can be easily referenced in team post-mortems. This takes place at the same time xMatters is triggering the rollback, so responders don’t have to choose between taking immediate remediation action or starting full timeline documentation in your service desk.
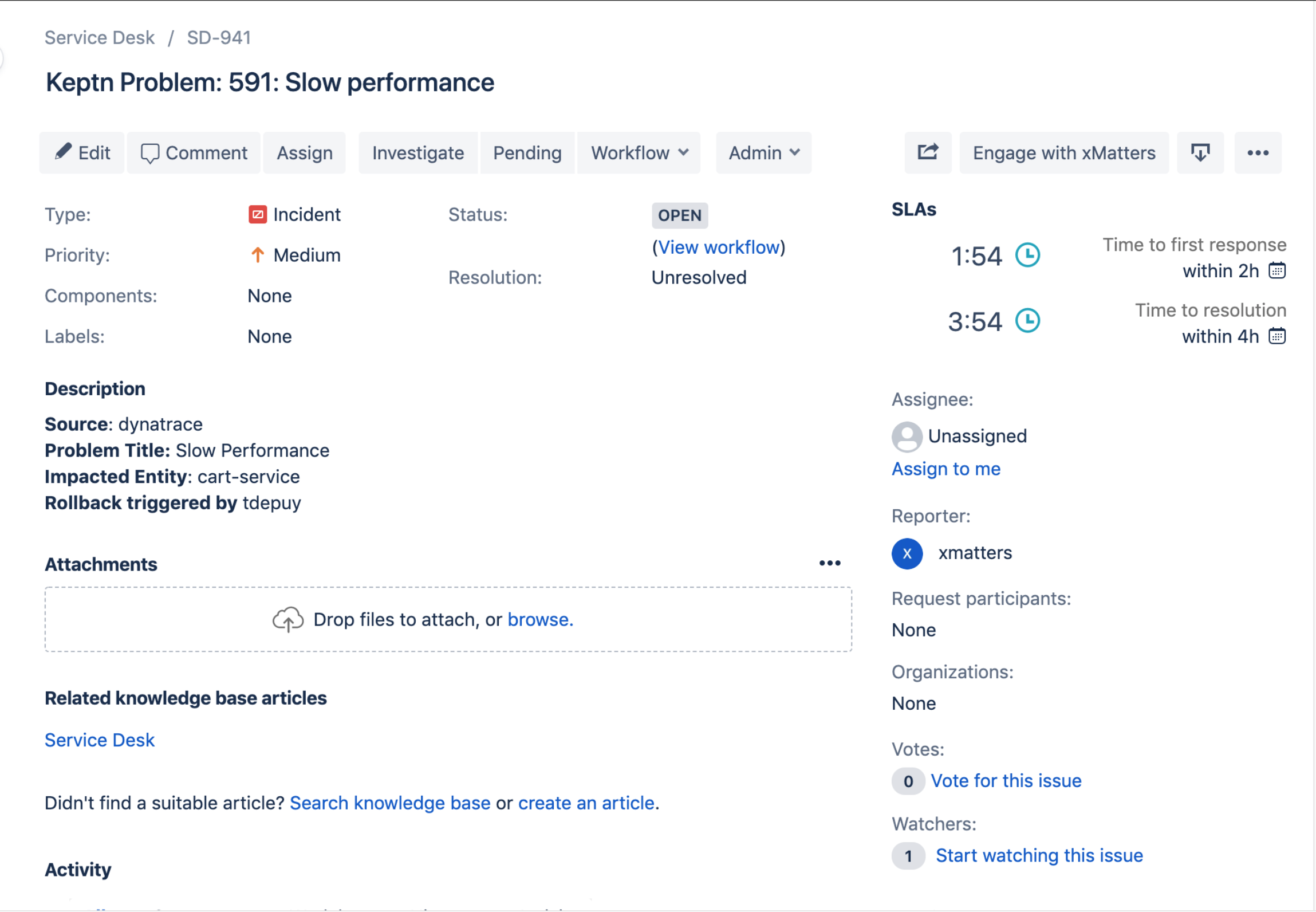
xMatters creates a Jira Service Desk ticket and passes through related information to capture data across tools and automatically update based on actions taken.
Step 5 | ChatOps
Because the release error has impacted services owned by other developers, xMatters spins up a dedicated Slack channel where you select the relevant teams to invite to the channel. All of the incident information is pushed into the channel through xMatters, so those who join get immediate context. As you collaborate in chat, on-call resources can also use the xMatters bot to update the related service desk ticket. The full chat transcript from this channel will also be automatically appended to the service desk ticket once the issue is resolved, giving you even more detail for your post-mortem exercise.
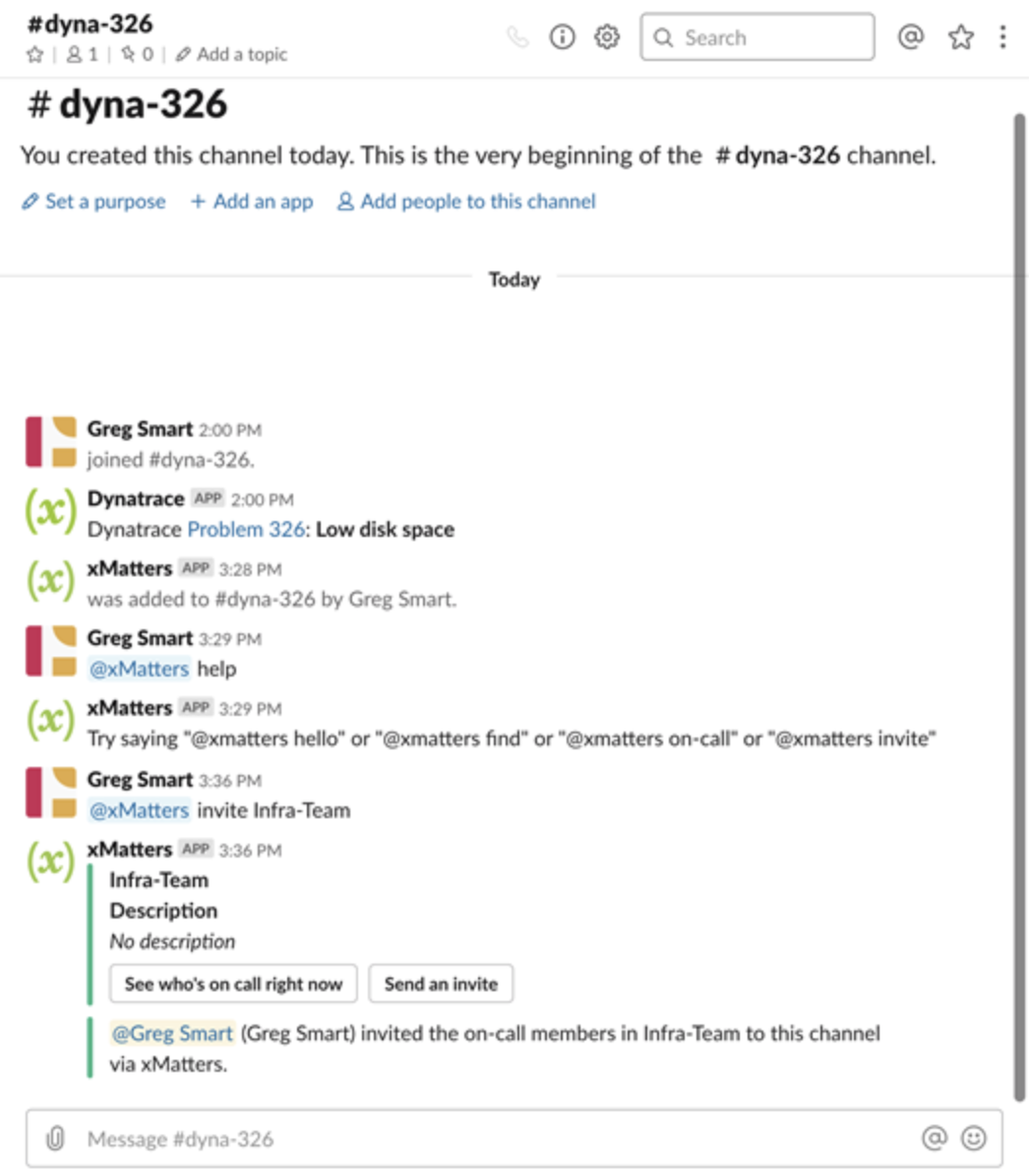
After starting a dedicated Slack channel, the xMatters Slackbot pulls the on-call database to invite the right resources to the channel,
Step 6 | Rollback Execution
Within moments of pushing the xMatters response button to launch the remediation workflow, the rollback to the previous, stable version in the green environment is executed through keptn, fixing the issue just minutes from detection. With the incident resolved, the related chat channels and service desk issues are automatically closed.
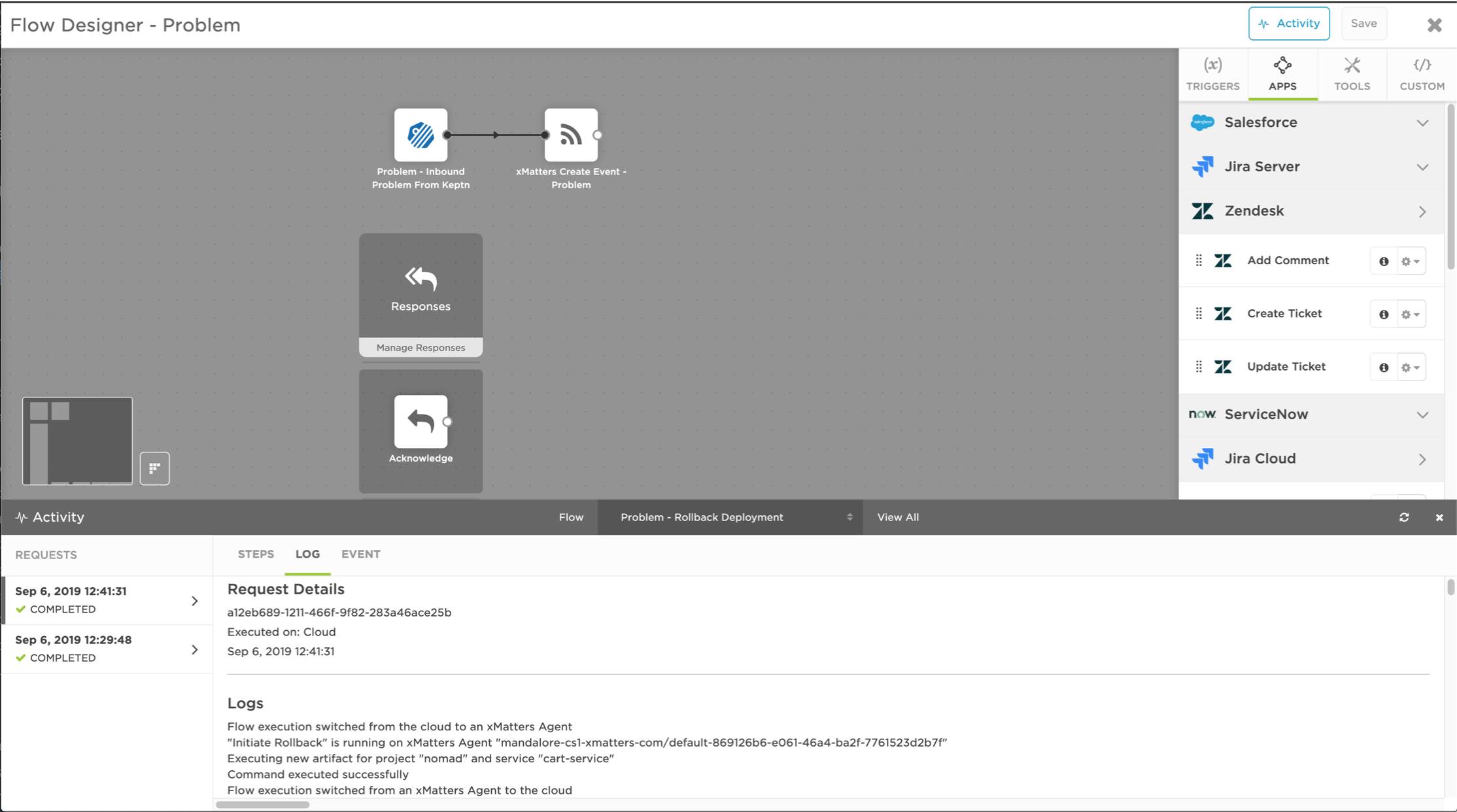
Per the remediation workflow built in xMatters Flow Designer, responders have the option to execute a rollback through keptn – all through their mobile devices.
Step 7 | Post-Mortem and Reporting
Once the incident is resolved and versioning rolled back to the green environment, it’s time to look at what happened, how you responded, and how to prevent things like this in the future. Because xMatters automatically appended and updated your incident management systems – from chat to service desk to monitoring – with the incident information and steps taken to resolve, the development team has easy reference to this during the post-mortem meeting. Furthermore, as xMatters retains historical incident data, you can quickly cross-reference similar incidents to identify any patterns of issues to better prevent future incidents. User-level analytics in xMatters help you know which team members broke their personal record for mean time to respond.
Continuous Deployment, Continuous Self-Healing
Pushing releases at break-neck speeds to keep pace with innovation is not for the faint of heart. The possibility of what could go wrong is just as present as the excitement around shipping the code in the first place. By creating parallel environments, developers get the benefit of being able to roll back to the previous, stable version of any release. The ability to do this in an instant, when customers are counting, is critical. Giving on-call developers the ability to execute a rollback with the push of a button provides a safety net for teams that need to quickly and frequently release new services. No need to break into a cold sweat with your next release; If anything goes wrong, you can now push a button and get everything back to working order so quickly, your customers won’t even notice anything happened.
Ready to eliminate risk and enhance your innovation?