After a Deployment Error, Should You Fix Forward or Roll Back?

Categories
DevOps & SRE
This can’t be good.
You open your eyes to the sound of your phone, bleating at you from your bedside table. This can’t be good, you think to yourself, as the adrenalin starts to flow. The glowing red numbers staring back at you from the clock read 4:48am.
As you settle down into your chair and unlock your laptop, the bright light from your screen seems blinding. A couple of minutes later, you’re on the conference bridge for an incident. You gather that a key component of your infrastructure is failing due to an upgrade the day before, your customers’ messages are not being processed, and they’re furious about it.
Engineers responsible for the component are testing some hypothesis, and asking for time to fix it. “Maybe if… I bet we can…” Meanwhile, senior management are on the call, and have to field tough questions from customers, and they want to pull the plug on this change and roll back, getting customers back online ASAP. Engineering isn’t so sure, saying that the nature of the change makes rollback a dicey proposition. They turn to you for your opinion.
What do you say?
Understand your options
Being stuck in this position can be daunting, and there isn’t always an easy answer. Fixing your components in-place means you can move forward after this incident; and once it’s fixed, that’s (hopefully) the end of your remediation. But, this costs time while your services are offline, leaving your customers unserved and unsatisfied.
On the other hand, rolling back the change might be quick (depending on your deployment strategy), but unless you intend to permanently freeze there, you still need to get that change out, and soon. There’s additional remediation work required here to correct the change, perform the requisite QA, and re-deploy your changes into production.
When incidents happen, the time you’ve invested and the plans you’ve made preparing for it is key. Understanding the strategies available to you, and when to pursue them, will determine whether your recovery efforts are a success.
The Anna Karenina Principle of Deployments
Leo Tolstoy’s book Anna Karenina begins:
All happy families are alike; each unhappy family is unhappy in its own way.
This concept maps as well to software deployments as it does to dysfunctional 19th-century Russian families. When a rollout goes as planned, it looks like every other rollout: no errors to remediate, no disrupted services to restore, just new bug fixes or features available for use. On the other hand, when a deployment goes poorly, any number of scenarios might unfold. Consider the following:
An upgrade to your messaging bus leaves consumers struggling to get messages from their queues. The messaging bus runs on VMs, which were upgraded in place.
A change to an internal data format was rolled out at 4pm Pacific Time, and everything seemed fine until 8am Eastern Time, when your largest customers began feeding traffic to your system. Too late, you realize what the computational cost of processing this new format looks like under heavy load. By now, you have 13 hours worth of data in the new format, which amounts to tens of thousands of transactions.
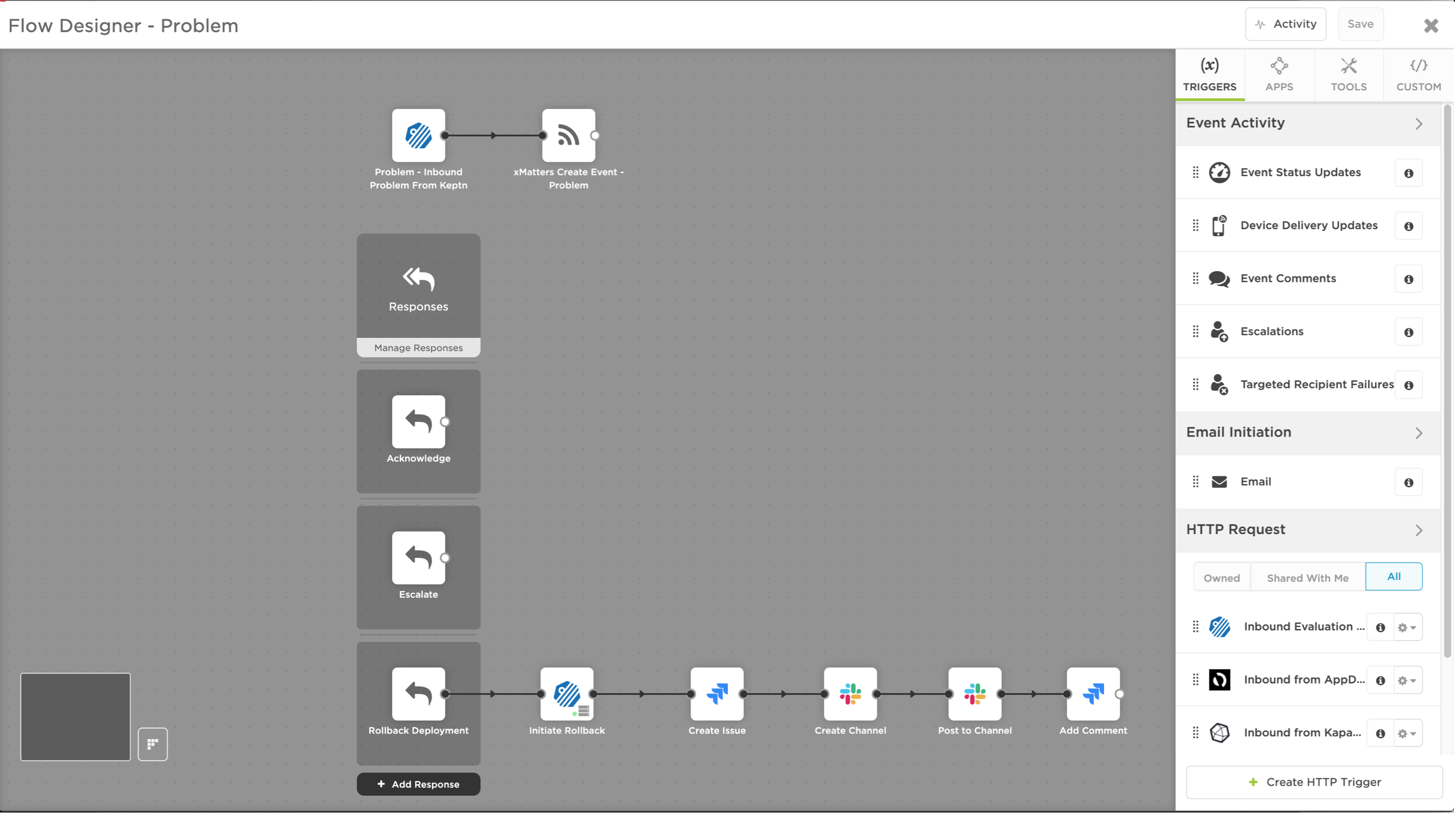
An example of how xMatters Flow Designer – and in this case Dynatrace – removes the stress from blue-green deployments.
An update to a service that was just deployed contains a bug that is destabilizing your customers’ environments. Because your CI/CD pipelines follow a blue-green deployment pattern, a rollback is technically straightforward, but there’s a hitch. The new update includes new functionality which you are contractually committed to providing to some key customers, and rolling back means missing your deadlines.
Each of these situations might require a different response from your organization, based on the options available to you. Ensure you know what those options are before deploying the change.
What are your Options?
When dealing with a failure scenario, your ability to recover is only as good as the effort you’ve invested in developing your recovery options. Careful planning and preparation give you options for how you deal with an incident, and will guide you on the path to successfully restoring your services to customers.

Reverting a Change
By far, the simplest solution to resolving a problem is usually to revert the change, and go back to running the previous version of the service or configuration. How this works depends on the service and the nature of the change, as well as the extent to which you’ve effectively prepared to implement a rollback. Some examples of reverting a change include:
- Running a rollback script against the database to remove a new index
- Removing the new version of a service from a load balancer pool
- Disabling a feature flag that exposed customers to new functionality
With proper planning, many changes can be reverted quickly and safely, with little or no impact on your uptime and service delivery. Wherever possible, reverting a change that is causing a customer incident should be the initial plan of attack.
Failover to a Secondary Environment
In some cases, it’s just not as simple as reverting a change. An example of this is when there is, in fact, no change in play, and the incident is caused by some external factor, such as a change in your application traffic pattern, or a hardware failure in your datacenter. In these scenarios, having a secondary or DR environment available to you gives you the option to redirect application traffic away from the problem area of your application stack, and instead process traffic in a different logical or geographic area. Such a change may involve some orchestration in your application stack, such as simultaneously promoting a new leader in your database cluster while rerouting traffic at your load balancers. While somewhat complex, investing in the ability to leverage a secondary environment can be particularly advantageous when the cause of your failure is nebulous or out of your control, or the path to reverting your change is onerous and time-consuming.
Fix Forward
As a last resort, you might need to forgo the rollback plans, and simply fix the issue in place. The challenge with deciding to fix an issue in place is until you know how to fix the issue – until you can diagnose and remediate the issue, and then deploy a fix – your customers will continue to experience its effects.

Feature Flags

Dark Launches

Canary Releases

Blue-Green Deployment
Developing Options for Rollback
When planning a change in your software environment, there are several approaches that lower the barrier to rollback in the event of a catastrophic failure. We’re going to briefly discuss feature flags and dark launches, canary releases, and blue-green deployments.
Feature flags
Feature flags and dark launches: Deploying your changes behind a feature flag is a method of controlling the exposure of your change to your customers. In such a scenario, a new feature or change is deployed to your customer’s application environment, but is disabled by default. Such a deployment is called a dark launch, and is a popular strategy for managing the risk associated with new application functionality.
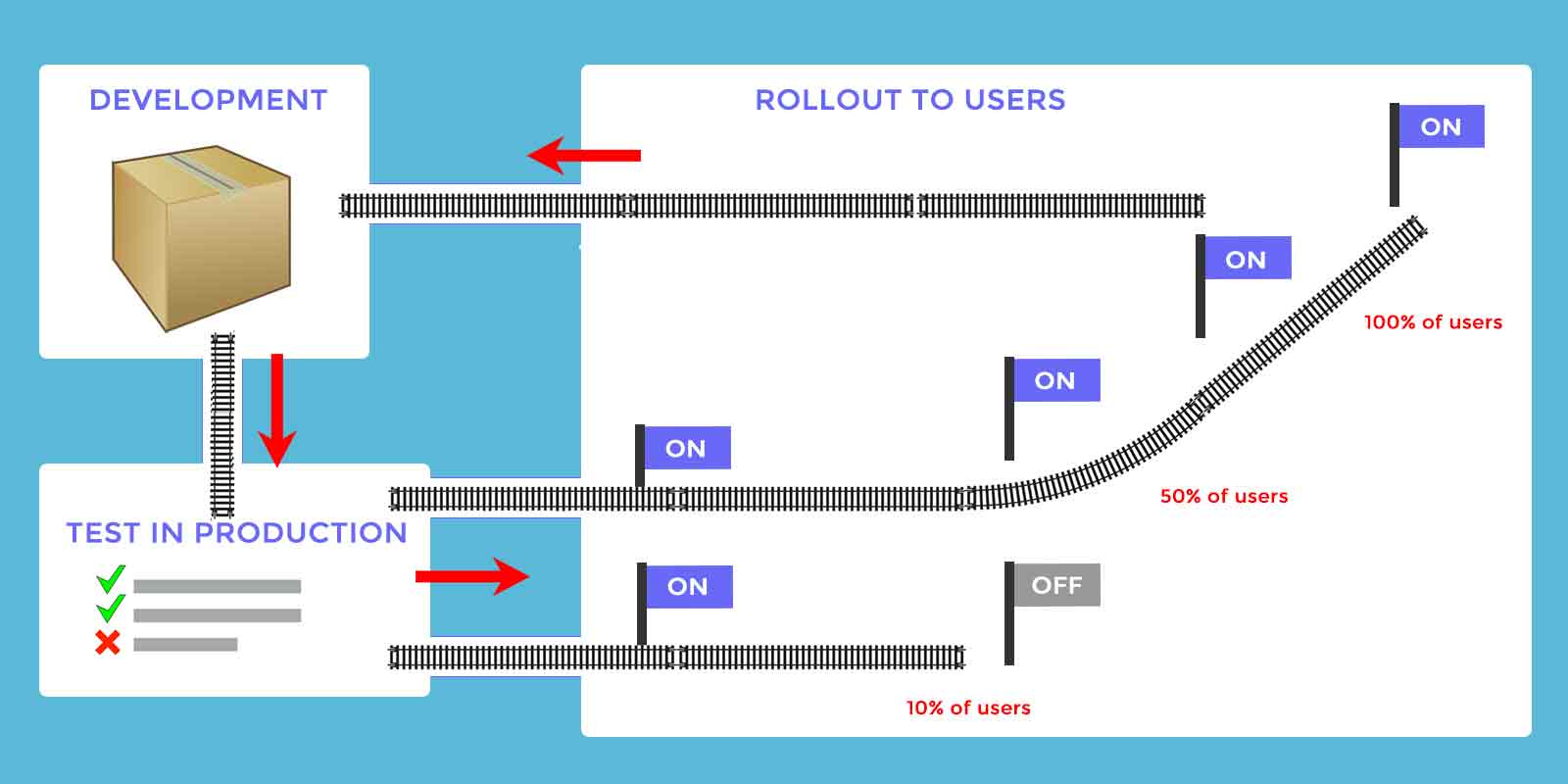
Canary releases
Canary releases: A canary release involves exposing the darkly-launched functionality to a certain segment of your customers, and evaluating the results. This approach can be highly effective not only for limiting the impact of defects in code, but also for evaluating customers’ responses to changes on a small scale before exposing those changes to a larger audience.
Blue-green deployments
Blue-Green Deployments: In order to roll back a change, it’s important that you have something to roll back to. In-place upgrades to software or cloud infrastructure can obliterate the previous working version, leaving you without a viable rollback target. Blue-green deployments involve deploying the new services in parallel with the existing services, then rerouting traffic to the new services. Not unlike a canary release, blue-green deployment can be done in stages, rather than rerouting all traffic at once. A newly deployed service may initially get 2% of the traffic, then 10%, then 50%, and finally 100%, all while your team monitors error rates for unwanted patterns. Retaining the previous version of a service until the next deployment means that, at any time, traffic could be rerouted back to the old service version to mitigate the impact of a bug.
When to Fix Forward
If none of the rollback strategies described above are available to you, you may be stuck with fixing the issue in place. Some changes simply don’t lend themselves well to rollback, such as:
- Changing a communication protocol between two (or more) components in your application stack, where the clients become dependent on the new protocol and are unable to revert to the previous one
- Changes to a database schema that were destructive on the original data (e.g., rewriting source data in a new format), or schema changes that client services depend on for their new features to function correctly
- Upgrades to components of your application stack which do not gracefully lend themselves to a blue-green deployment strategy, such as databases and message brokers
Because of the perilous nature of a fix-forward strategy, it’s worth the time to identify those areas of your environment that don’t allow for rollback, and look for opportunities to redesign them, with the goal of making rollbacks simple and safe.
Have an Incident Management Plan
Having a strategy planned out before an incident occurs is your best bet for balancing the internal impact of your remediation against the service level you provide to customers. For example, your plan can include an initial response where you attempt to identify and fix the issue in place, but that effort is timeboxed to 30 minutes, after which a rollback is performed to quickly restore service. This planned response can vary based on the customers impacted, the particular component in your system that’s affected, or some other parameter; regardless of the specifics, planning in advance for failure scenarios gives you a framework to guide decisions when under pressure.
Document your Strategies in Runbooks
In an incident response scenario, your remediation strategies are only as good as your ability to execute them in the moment. Too often, individuals in an organization become subject matter experts in a service, but then fail to disseminate key knowledge for dealing the service in an incident, and become a single point of failure in the incident response. One effective method for turning this tribal knowledge into institutional knowledge is to document incident response plans in runbooks, which give newcomers to your service simple, step-by-step processes to follow to address an issue. In the case of a rollback, having instructions on how to disable a feature flag or revert to a previous version are likely to reduce the time required to correct an issue, as well as reduce the stress on the personnel tasked with performing the fix.
Conclusion
Downtime incidents are stressful for both you and your customers, and resolving them quickly and effectively depends on understanding the options available to you, as well as having a plan to implement them. Fixing an issue in place or rolling back a change each have their own set of pros and cons, and must be measured against the specifics of the incident. Creating options for rolling back changes, understanding the boundaries of a fix-forward strategy, and advance planning of how to manage an ongoing incident are the best tools you have available to restore your system within your SLAs, and keep your customers happy.
Whether you’re rolling your deployment back or fixing it forward, time matters. Some common ways to gain efficiencies include getting critical information to the right people, using templated workflows, and automation. If you’re an xMatters customer, you can use scenarios to develop templates and response counts for different situations. You can use Flow Designer to build drag-and-drop workflows for repeatable, scalable processes for complex situations. You can execute automated remediation for things like process crashes, full disk prevention, and blue-green deployment rollback.
Try it yourself!