The Fundamentals of Enterprise Incident Management

Categories
Incident Management
In the world of enterprise major incident management, integrating partial or full automation across each stage of the incident response and management lifecycle makes a big difference to the speed incidents are addressed and the data you have to understand them afterward.
Gartner coined the term “Incident Response Automation” in its 2020 report Automate Incident Response to Enhance Incident Management. “As organizations increase in reliance on DevOps toolchains like continuous integration/continuous delivery (CI/CD), solutions demand automated integration with incident management processes. Traditional incident management models cannot meet the needs of agile cultures because of the manual tasks in the incident response workflow.”
Some may ask: Why do you need automated incident response and management? Aren’t DevOps teams and SREs able to tackle most failures? Why do big enterprises like streaming services, banks, and major retailers focus on the monitoring and automation of incidents?
Let’s take a quick look at a possible failure scenario:
You’re a DevOps engineer for a company whose business and reach are mostly online. Everything seems to be operating the way it should, so you pack up and finish your workday, only to receive an urgent message from your CEO. She’s experiencing issues trying to use the company’s mobile app.
You check the logs and reply that it should be a minor issue and it’ll be resolved soon.
Checking back 90 minutes later, you find that you can’t access the app at all and your business is experiencing a global outage because of a failed application service or unresponsive API. Surprised and frustrated, you log back in and try to fix the issue without fully understanding what happened. In modern microservices applications, the failure point could happen among any of the hundreds of clusters—possibly spread across multiple cloud platforms.
Your quiet evening is ruined and there’s no way of knowing how long this issue will persist.

The essential steps in the Mean Time to Resolution (MTTR).
Now imagine this scenario if you had automation capabilities with your business application connected to your incident response and management platform. As soon as the monitoring tools detect that the system is experiencing a failure, an alert is raised and you receive a notification detailing exactly what’s happening, with links to the resources you need to understand and follow up. Right from your notification, you can launch automated prevention measures, such as restarting the service or failing over to a backup system. Further notifications are sent automatically to relevant team members who can investigate and mitigate within their areas of expertise.
Automation just helped you prevent a global business outage, and provided the details you’ll want for a postmortem when you check in with your team.
That’s just one example of what automated incident response and management can do and how it adds tremendous value when a major—or minor—incident happens.
With xMatters, you can leverage a scalable incident response and management model to address incidents across your enterprise using automation to speed responsiveness, gather data from diverse tools, and take the tedium out of manual practices.
Why Do Incidents Occur?
In spite of your DevOps team’s best efforts, there is always a possibility for incidents to occur. Each time you build, deploy and operate software, there is a risk of incidents. The increased complexities within infrastructure environments and the additional abstractions that are layered within applications and services have made the need for incident response and management more crucial than ever.
Common causes of incidents include events such as:
Broken builds: Generally broken builds are expected, it may be a missing library dependency or a gap in testing. However, when builds break frequently, it’s a sign that the team should review its development process and deployment pipeline, as those are the most common places this issue starts to appear.
Failed deployments: These may arise when the network or the target hosting environment is faulty. It may be due to a lack of security permissions, insufficient memory or disk space, or the server not being ready for deployment. Whatever the reason, code was deployed and it is not working.
Application bugs: Source code quality is critical for any successful business. You can implement all the unit tests, acceptance tests, integration tests and various others to ensure the development team is building the right product. But you won’t catch every bug every time. With new products and fast-changing software specifications, bugs sneak into production.
DDoS attacks: Unfortunately, there is no shortage of hackers and malicious software ready to exploit vulnerabilities. A distributed denial-of-service (DDoS) attack can flood a system’s bandwidth and harm the business even if the software is free of bugs.
Complex environments: Modern development and deployment environments are built on many interconnected components: Docker containers, microservices, Kubernetes deployments, cloud platforms, and more. Given all these moving pieces, it’s easy for even a single small error to slip through the cracks and break an entire release.These tools offer convenience and scalability, but they also introduce many new points of failure. Every one of these components needs time and attention from your DevOps team.
Where Automated Enterprise Incident Management Adds Value
There are so many possible vectors for incidents to occur. How do you maintain visibility and respond to incidents in complex application environments?
One way is a manual approach: each time an incident occurs, you scramble to fix it. Perhaps, after chasing the same problems, you come up with a series of steps to escalate and mitigate. Think of our earlier example—maybe you have a plan in place, but you’ll spend the weekend at your computer executing it.
A more efficient and scalable approach is to automate major incident response and management as much as possible. This makes it easier to respond to every incident and continuously learn from each one by collecting data, understanding team responses, and revisiting inputs in postmortems.
Automated enterprise incident management is particularly valuable for major incidents causing significant downtime, revenue loss, or security breaches. Reacting in a swift and organized manner is important, but stress in these situations can be high. Automation helps ease these major incidents in the heat of the moment, but also in the days after, when critical thinking and a neutral assessment of an organization’s infrastructure and team are important.
Think of an automated enterprise major incident management solution as a tool that helps team members make the optimal moves when it matters the most. When an incident occurs, it’s crucial that the right people are notified and provided with the right information. If something has failed or an error has occurred, an automated incident response triggers an alert that goes directly to the relevant on-call responders, helping them manage through the incident, and providing background information to improve their understanding of the incident and response in postmortem analysis.
At the same time, working with integrated monitoring tools, your automated response system can:
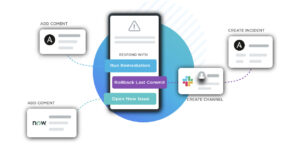
- Report log data identifying the failure condition
- Identify the code modules and builds related to the issue
- Send alerts to on-call employees
- Create a Jira ticket in the work backlog to cover remediation
- Create a Slack channel for incident response and real-time collaboration, or notify employees or other channels
- Post supporting information and response status to key stakeholders
- Collect incident details and remediation steps for postmortem analysis and discussion
Your automated response can even include kicking off further automated remediation steps like service restarts or backup failover.
Automated major incident management can provide higher efficiency and productivity throughout the organization as well as performance edge during sudden traffic spikes or possible denial of service attacks. When incidents occur, automated incident response can help organizations to be proactive and productive at the same time.
Implementing Automated Incident Response
Maybe the idea of implementing automated enterprise incident management sounds interesting to you, but how do you start?
Major incident management is only as good as the data it has available. Observability and monitoring are the key elements of an environment that provides enough data for successful incident management.
Start by making sure your systems are built with observability in mind: they’re instrumented in a way that lets your team understand and measure the internals of a system, providing insights that aid monitoring.
With observable systems, you can put reliable monitoring in place to gather indications of failures and data to understand and act on the failure indicators. There are many monitoring tools available today that give you visibility into current system state, including Datadog, Google Operations Suite, and Prometheus, all of which integrate with xMatters.
Your toolkit for communication and collaboration may already include services such as email, Slack, Microsoft Teams, Jira, and ServiceNow. xMatters ties together all the tools involved, such as development testing, operations, product management, and even business leadership. It gives you 360-degree scalable, adaptable, automated enterprise incident management capability.
xMatters offers a wide range of integrations with many of the tools you’re already using to plan, design, build, and run applications. When incidents occur you’ll be able to connect the dots from alerting the right people to automating processes that may be able to remediate the issue, such as creating service desk tickets or Jira issues. Your team will have access to the background data necessary for response to complicated incidents.
When using a tool like xMatters, you can reduce response times, coordinate communication, and employ automation you already have on hand to make sure you fix problems faster.
Next Steps
As organizations like yours move deeper into digital transformation, you should be aware of potential problems that could disrupt operations. Automated incident response is critical for teams to detect issues, alert responders, and solve incidents as quickly as possible. This helps keep the team focused on new features and improvements, with happier customers enjoying a more reliable digital service.
As we’ve seen, integration doesn’t have to be difficult. To find out how easily automated enterprise major incident management is with xMatters, request a demo today.